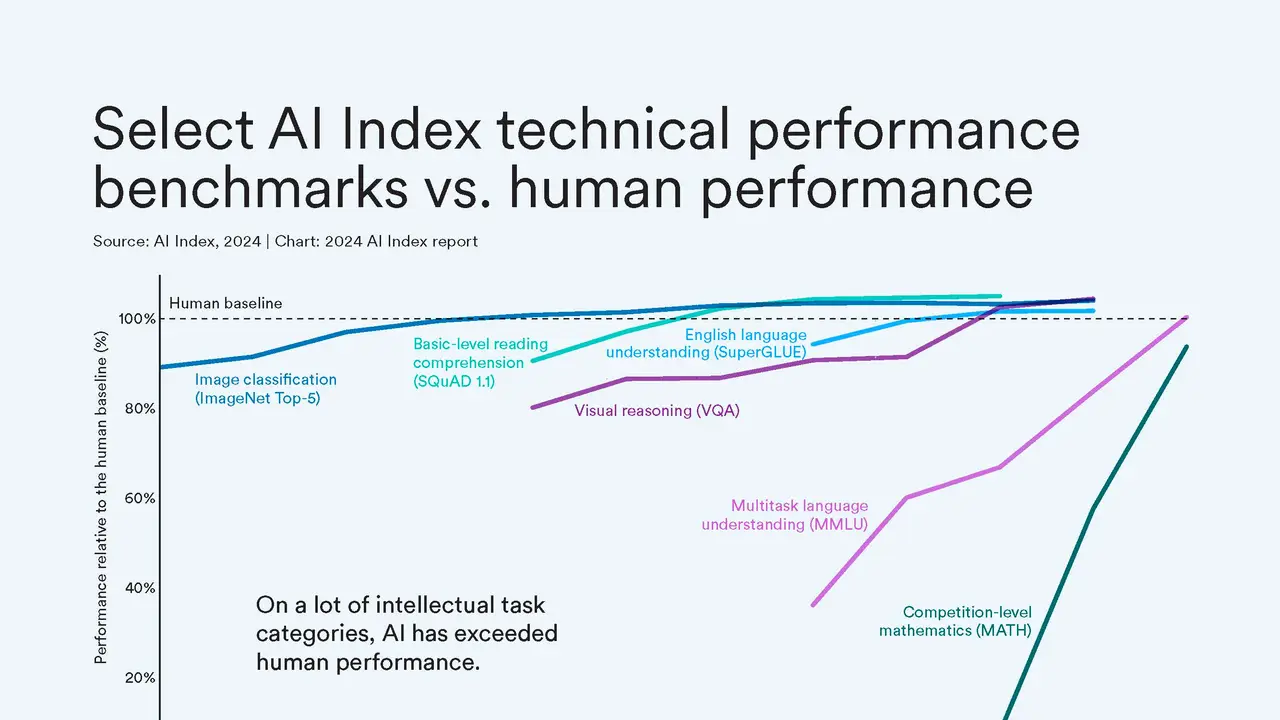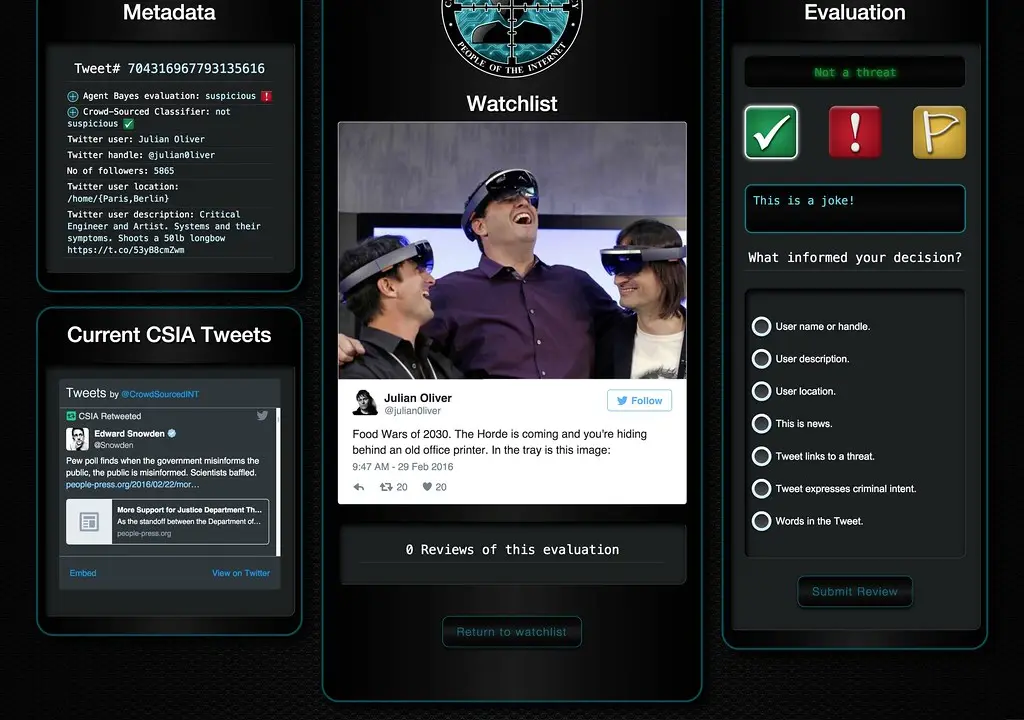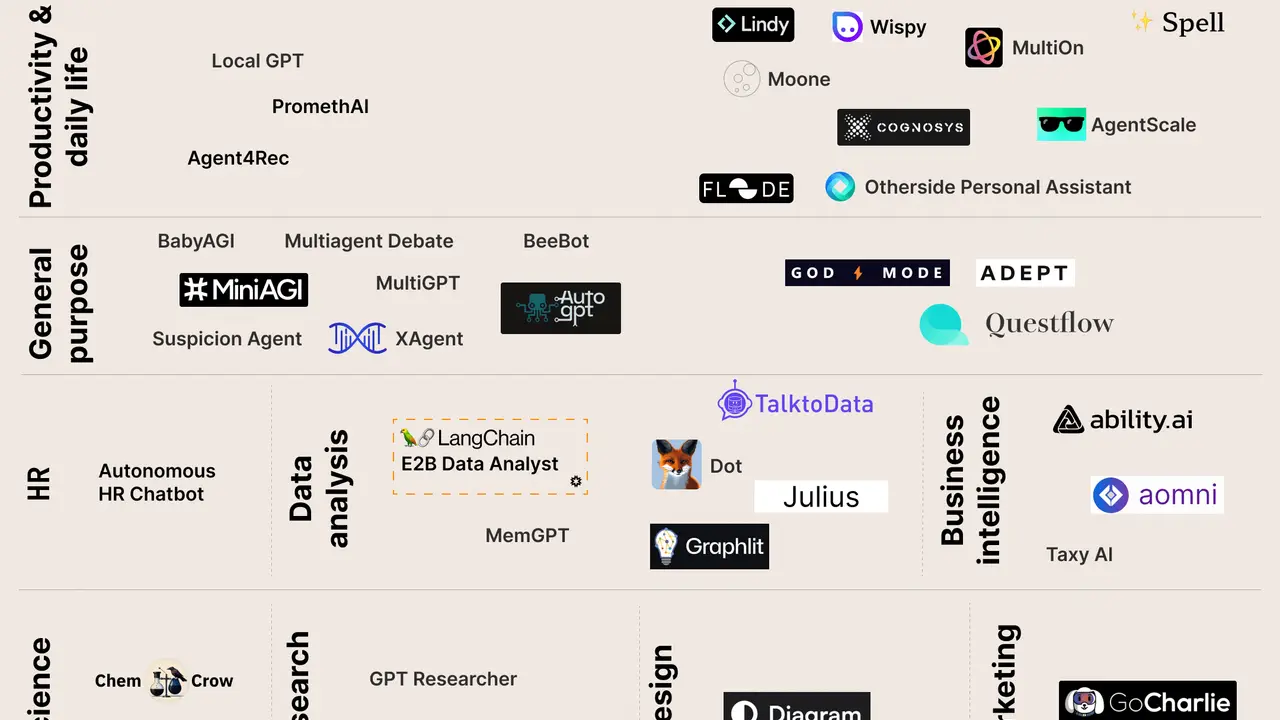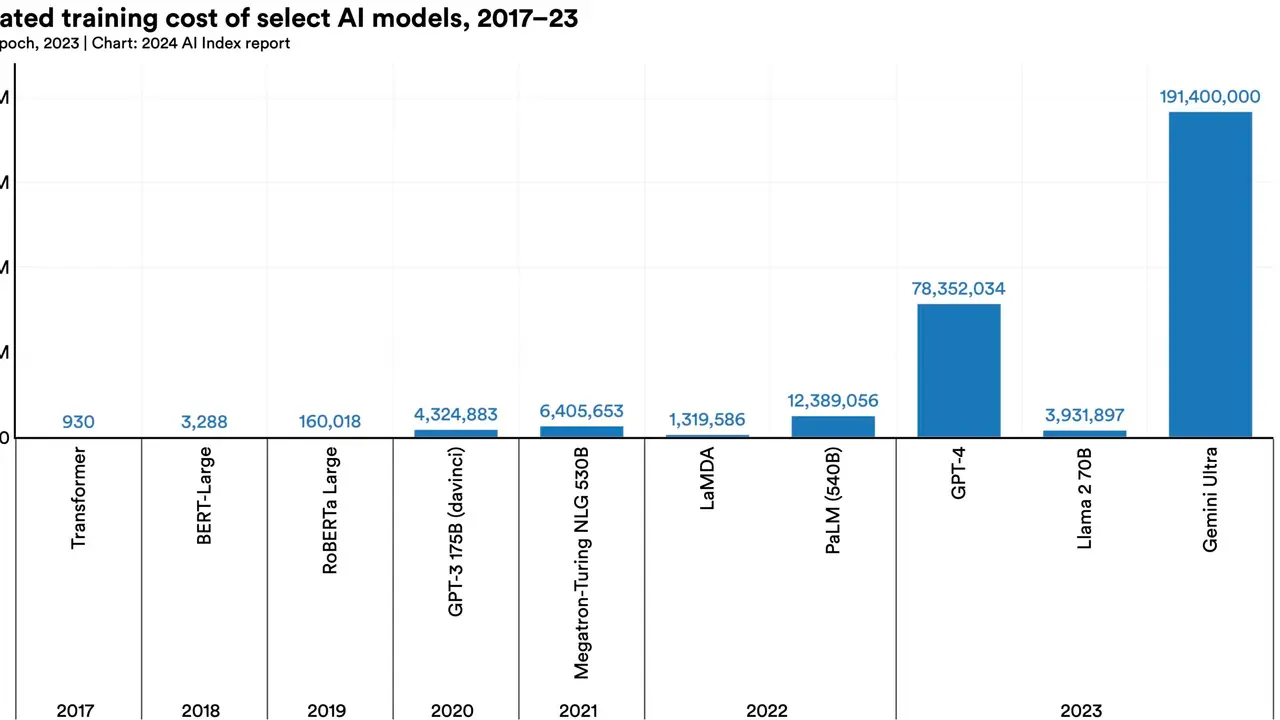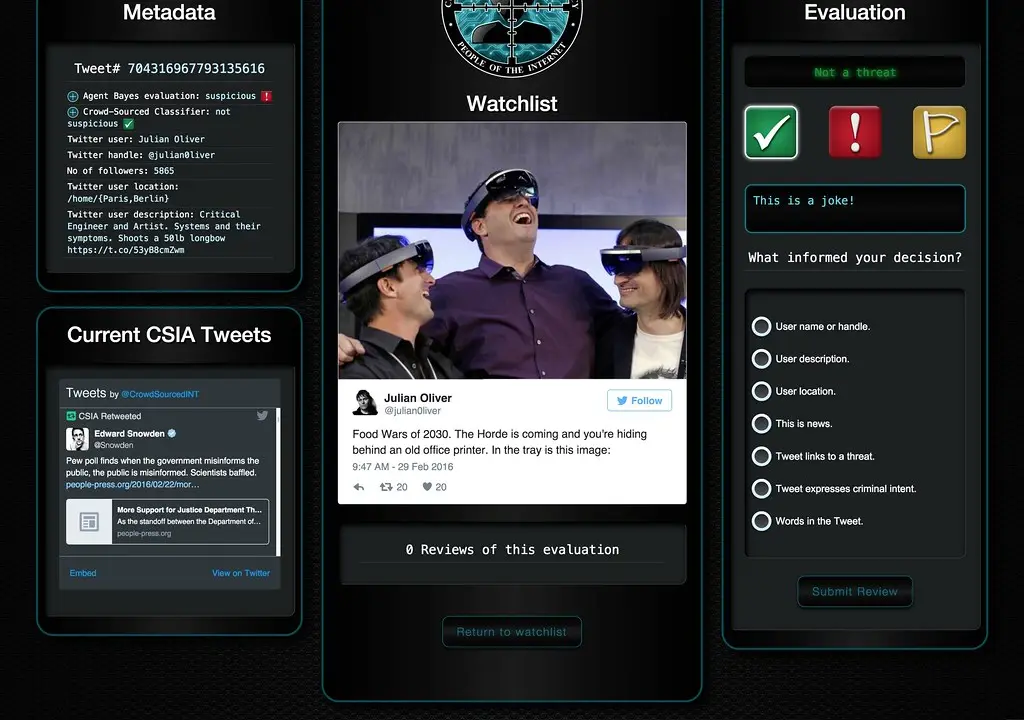
Securing AI Agents in 2026: Identity, Least Privilege and the OWASP Agentic Top 10
An agent that can act on your behalf is a new attack surface. Here are the 2026 guardrails that actually work: agent identity, least privilege, and approval gates.
8 min